天文学中的数值模拟:从千年模拟说开去
在宇宙学研究中,在计算机上进行数值模拟是个重要的手段,千年模拟(Millennium Simulation)正是现今在相关工作中的代表。这项结果于2005年公布的模拟动用了21603个粒子参与,力求再现冷暗物质模型下的星系形成与演化过程,以图为观测提供比照对象,来检验当前的宇宙学理论,解释斯隆等大型巡天计划的结果,并回答宇宙的演化与星系的形成、暗物质与暗能量的性质等基本问题。

冷暗物质模型是如今星系形成的主流理论。在这一框架下,今天在宇宙中所见的复杂结构起源于大爆炸后不久的密度涨落。密度涨落的生长,特别是后期生长,有着很强的非线性。由于其中的过程复杂,计算机模拟几乎是进行理论预言与验证的不二法门。
宇宙中物质的主导是只与其他粒子有引力作用的暗物质,因此一般的宇宙大尺度数值模拟工作往往会将物质背景近似成为离散的暗物质点,千年模拟亦不例外。考虑大尺度结构演化过程的时空跨度之大,对模拟工作的要求也自然是规模越大越好。理论上说粒子越多,结果也就越精确。
21603这个数字乍看起来可能不是太大,不过也是1010的数量级了,比之前任何类似模拟的规模至少大上10倍。模拟区域的尺度是随时间演化的,边长是500/h兆秒差距,其中的h表示哈勃常数除以100,时间范围则是从红移z=127到今天(z=0)。
进行千年模拟的程序名为GADGET,早期版本GADGET-1是千年模拟的领头人物Volker Springel在博士期间的一项工作,现在则发展到了GADGET-2,其基本代码遵循GPL协议公开,任何人都可以下载使用,据称也可以在当前的任何计算机上运行。GADGET的核心是TreeSPH算法。在说TreeSPH是怎么一回事之前,不妨先来看看N体模拟的常用算法。
最简单最直观同时也是最消耗资源的就是粒子—粒子(PP)模拟,对于一个粒子,先要计算其他粒子对它的合力,然后根据合力求出运动状态。如果有N个粒子,那么在每个时间点上,对单个粒子求算作用力的过程就要进行N-1次,对整个系统的次数则是N2的量级。如果N足够大,这个数字相当惊人,因此PP模拟一般只用在粒子数目较少的场合。之前介绍的GRAPE相关工作也是利用PP算法完成的,只是借助了专用硬件设备加速了计算。
速度最快的则是粒子—网格法(PM)。顾名思义,该算法引入了网格,将粒子质量折算于网格上,并求出网格对各个粒子的势与作用力,折算方法要求尽量减少近场粒子作用力的波动。PM算法的缺点是对近场粒子的精度不高,因此又有粒子—粒子/粒子—网格法(P3M)问世,在近场(一般选为3倍格点间距)逐一计算粒子之间的作用力,远场按网格法进行。
Tree算法在天体物理中应用比较广泛,它的基本思路与P3M比较类似,将粒子间的作用力分为近场和远场分别处理。近场可以逐一累加计算,远场则是先将模拟区域由粗到细分为树状结构,根据与粒子的距离确定子域大小(越远越粗糙),根据子域内粒子分布计算其总质量与质心,再求出折合的质心对某个粒子的作用力。对于N个粒子,每步的计算量相当于N logN,当然比N2少了很多。这种方法应该就是GADGET所采用的,考虑千年模拟的1010个粒子,不难想象其计算量有多大——实际情况是,动用了IBM p690超级计算机的512个处理器连续工作了一个月之久,产生的总数据量也达到了惊人的25 TB。当然这批数据能一直挖掘到现在,也算是捞回了成本。其实Tree算法还有另一种变体,计算量仍旧是N logN,只是子域划分是由粒子对起,从细到粗。
说完N体算法再来说说这个SPH的事情,GADGET主要用它来进行气体动力学的计算。SPH全称光滑粒子流体动力学,最初是为解决天文问题而开发的。传统上求解流体问题的方法无外乎建立网格,求解差分方程。但这样的方法有自己的缺陷,碰到存在物理量跳变、结构离解等情况的问题就不能很好地解决(如简单的水滴溅出过程就难以用传统算法模拟出来)。SPH干脆完全撤掉网格,把计算对象近似为有分布的粒子群,这样粒子的所在就可以很好地体现实际的物质所在而不必受限于网格,同时由于单个粒子自身并非质点而是以某种形式的分布存在,又兼顾了连续性,因此可以获得更高的精度。
当然实际用于千年模拟的程序并仅仅不是网络上公开的代码,而是在其中增加了更多的非引力因素,如星系的反馈机制。下面这张图就是千年模拟得出的宇宙结构,从下往上逐一放大。图中可见在大尺度上,暗物质的分布几乎是均匀的。随着尺度的缩小,暗物质团块以及纤维的结构显露了出来,并有星系团出现。最上面的一栏是星系团晕周围的放大图。

图片来源:Springel et al. (2005)
对于星系研究,千年模拟的重要结论是,在冷暗物质框架下,中心拥有特大质量恒星的星系看起来可以形成得足够早,因此可以解释当下所见的类星体。根据星系中央特大质量黑洞与星系核球之间的关系,最明亮的类星体应该是质量最大的星系,在模拟结果中筛选类星体的标准也是基于这个原理制定的,包括暗物质质量、恒星质量和产星速率,几种标准选出的天体相互吻合得比较好。值得一提的是,可以将筛选出的一个可能的类星体追溯到红移为16.7的时候,这属于最早出现的结构之一,它在真实宇宙中的对应体也被认为是寻找宇宙早期恒星及特大质量黑洞的最佳地点。

左:模拟得到的暗物质分布;右:根据半解析模型得出的星系分布(散点图,圆点大小表示星系中恒星的质量,颜色表示星系在本地坐标系中的色指数)与暗物质分布(灰度图)的比较。最的星系位于暗物质最为密集的地方。在宇宙的早期,由于产星活动剧烈,星系大都偏蓝。(图片来源:Springel et al. 2005)
为追踪星系形成和演化过程,千年模拟在N体算法之外追加了半解析模拟,所得的一些结论与SDSS与2dFGRS等巡天结果符合得还不错,如颜色与亮度之间存在的幂律关系。至于更偏重宇宙学的部分实在是讲不来,毕竟本人对这些内容了解不多……
除了千年模拟,GADGET从事过的工作还有很多,如下面这个星系碰撞过程的模拟:
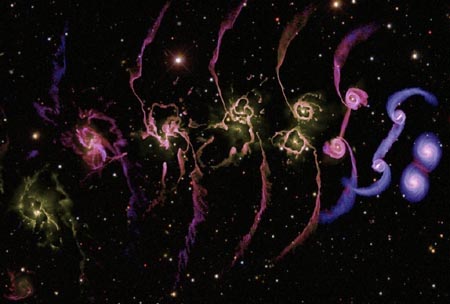
图片来源:Tiziana Di Matteo, Volker Springel and Lars Hernquist (2005)
再举两个宇宙学数值模拟的例子。下面是率先考虑黑洞的模拟工作,由卡耐基梅隆大学的理论家Tiziana Di Matteo牵头,右图中箭头所指代表黑洞的所在:

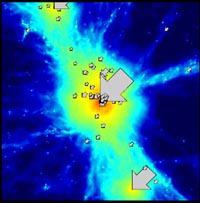
图片提供:Carnegie Mellon University
这项工作的基础程序照样是GADGET-2,不过在星系的中心增加了描述黑洞的种子代码,并考虑了黑洞相关的物理过程,如吸积。由于星系会频繁碰撞并合,黑洞在其中发挥了自己的作用,使得得出的演化行为与只考虑引力的传统模拟有所不同。
千年模拟在发表时的规模首屈一指,但现在已经不再是最大的N体宇宙学工作了。稍后发表的地平线(Horizon)模拟计算了40963个粒子,覆盖尺度约合整个可见宇宙的一半。在这项工作中,银河系这样的星系是用100个左右的暗物质粒子来描述的。

地平线模拟得到的宇宙大尺度结构全天图,对应红移z=0.9。(图片提供:The Horizon Project)
地平线模拟的基础程序RAMSES是根据粒子网格来计算粒子行为,用黎曼方法解决流体问题,考虑了超新星、离子冷却和加热、恒星形成等问题,并采用了自适应网格方法划分模拟区域。这是N体模拟的又一种常用思路。与千年模拟相比,地平线起用的硬件也更为惊人,在法国CEA超级计算中心的BULL超级计算机上利用6144个CPU运行了两个月。
用数值模拟的方法来研究宇宙学大致是开始于20世纪80年代,那时的结果第一次暗示,观测所见的大尺度结构必须借助冷暗物质才能形成。限于计算机发展水平,当年的模拟规模都不大,几万个粒子而已,搜索旧文的话还可以找到大量关于算法以及物理机制的讨论。短短20几年时间,这个领域的进展之快不由得让人感慨。最后用一张1985年的模拟图作为本文的结尾,图中c部分是真实观测的结果,注意其与a、b两种数值模型的相似之处:
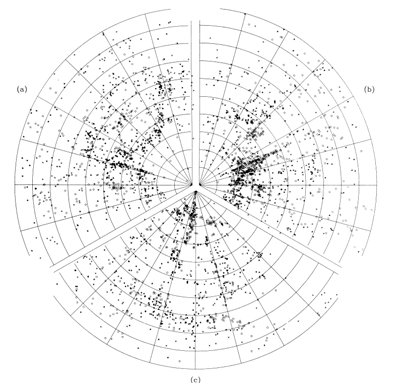
图片来源:Davis et al. (1985)