FITS沉思录
普适图像传输系统(FITS)自20世纪70年代问世以来,就一直垄断着天文数据,特别是光学天文数据的采集、处理、存储和传输工作。FITS格式的定义简单明确、跨平台能力强、相关软件积累丰富,同时“once FITS, always FITS”的前后一致性要求也为人津津乐道。随着时间的推移与技术的进步,FITS的应用范围日益普遍,不再局限于图像传输,而是涵盖了光谱、光变曲线、星表等类型的数据,像PSRFITS、OGIP之类基于FITS的特定领域专用格式也陆续问世;甚至FITS的影响力已经跨出了天文学研究的小圈子而不断向外拓展,比如欧洲空间局为梵蒂冈图书馆提供的馆藏资源数字化服务就是以FITS作为古籍善本存档方案的,这既充分利用了ESA多年以来应对天文空间科学数据的经验,也是出于FITS格式向前兼容性和开源性的考量。

工作人员正在对梵蒂冈图书馆馆藏古籍进行数字化扫描。(图片提供:Vatican Library)
但是FITS格式远非完美,就连它引以为傲的一致性也难保不会变成自身的沉重包袱;何况FITS这种小数据时代的产物是否能够满足当前需要还有待商榷。实际上,最早孕育FITS概念的射电天文学领域(特别是射电干涉阵观测)现如今因为需要面对的数据体量尤其大,复杂性也极高,已经变身为抛弃该格式的的急先锋。激进者如LOFAR、CHIME,还有中国的天籁阵列,从数据采集、处理再到存储归档的全过程早已无视FITS,全面转投HDF5等更适合高性能存储和运算的其他选择。
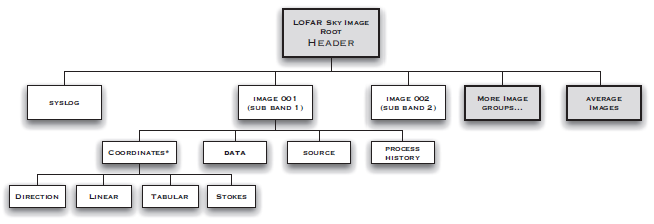
LOFAR的HDF5数据文件组织结构。根据与天籁团队的交流结果,天籁的数据格式要简单一些,并没有设置如此多的层次。(图片来源:Anderson et al. 2011)
在这样的形势下,FITS将何去何从?未来的天文学数据又将以何等形式示人?这关乎整个行业的发展,也与自己日后的工作任务直接相关。近来调研数据格式问题,读到2015年的一篇总结性论文,其中明确列出了FITS格式的是非功过,将其总结出来,也还是颇有启发性的。
是与功毋须多言,统一业内数据格式无论如何都是利人利己的好事;前后一致性更是保证最新的读写程序也能完全兼容数十年前的历史数据。但与此同时,文中又指明了FITS的七宗罪:
- 版本号不明:千万不要以为“once FITS, always FITS”的口号是零代价的。举例来说,虽然为了标榜前后一致,FITS不设版本号,但绝不等于着格式本身没有经历过任何变更,如文件头中的若干关键字已经被业内停用,但在性质上仍旧“合法”。这意味着日后所有的FITS文件读写软件必须能够支持这些早已过时的东西,无异于资源浪费;日积月累,混乱更是难以避免。照此下去,真真还不如短痛一时,明确规定好文件版本号,淘汰过于陈旧的部分,于开发者或是使用者都方便。
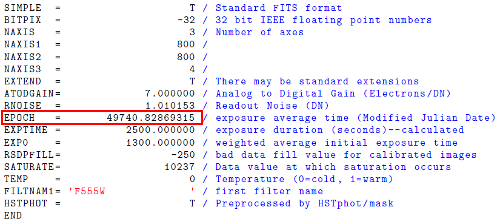
FITS头文件示例,其中的EPOCH即是现在仍旧合法但早已过时的关键词之一。(图片来源:Thomas et al. 2015)
- 存储内容的声明和定义混乱:官方对数据标准的定义过于简单,直接导致不同使用者各说各话的现象泛滥,通用的FITS操作程序编写难上加难。仅举一例,文件头中的某些关键字如TEMP,其真实含义就存在多种可能性,到底是“Temperature”还是“Temporary”还是其他什么东西的缩写,乍看之下真的就只有天晓得了。另外,各个天文台/项目组也往往还会定义大量外人看不懂(连组内人士不依赖详细注释的话都够呛能理解,但是注释这种东西嘛,就个人经历而言,身边的很多研究者真的就没有把它当作一回事啊……)的独有关键字写入文件头,估计要不了多久,正确解释这些数据的含义就要成为麻烦事了……
- 数据模型过于粗糙:数据模型描述的是计算机系统中的各个对象,以及对象的性质和相互关系。其实FITS根本谈不上什么数据模型一说,更不具备完善的“自描述”性质。甚至连科学研究离不开的误差、数据质量、获取和处理的历史、坐标定义以及单位定义,FITS的官方描述也是要么混乱不堪,要么在不同程度上无法应付实际需要。
- 元数据受限过多:FITS文件将元数据,如数据采集时间、所用仪器、观测目标、记录人员等信息存储在文件头中。按照规定,这些信息的书写格式是关键字(Key) = 数值(Value)。该形式本身就不能说是普适的,何况这里还有每个关键字不得超过8个ASCII字符、对应数值不得超过68个ASCII字符的限制。在关键字较多的场合下,使用缩写不可避免,可读性严重下降是必然结果。更且ASCII字符也不能满足所有需求,哪怕是记录天文学常用的波长单位——埃(Å)都无能为力,就不提写法可能各种稀奇古怪的各国人名了。这一条可不是在无理取闹,要知道,本人在国内天文圈子里就有姓名虽然不同,但英文拼写完全相同的同行。倘或我们二人有机会使用同一架仪器前后脚进行观测,其他人要如何凭借写在FITS文件头中的英文姓名来区分这究竟是谁家的东西?
- 针对数据本体的限制也不少:FITS的全名毕竟是普适图像传输系统,换句话说,它一开始是以单一一张完整的二维图像作为存储对象的。虽然后来FITS的一系列扩展陆续将1维光谱或光变曲线、3维DataCube以及与图像全然不沾边的数据表格纳入掌控中,但这种格式本身的天生局限性依然存在的。除了前面所说的数据模型粗糙,各种定义不明,有时FITS都无法合理而规范地表示不那么完美数据,例如怎样明确区分图像中的未观测天区和坏点?答案是尚无统一标准。此外,不同数据之间的关联和层级关系在FITS的体系下也难以被明晰展现。
- 大数据集操作困难:在FITS刚刚诞生的年代,天文界保存数据的主流设备是磁带机,因此与该格式绑定的顺序读写操作顺理成章。然而在数据爆炸的今天,像CHIME或天籁这样的阵列获取的每个文件体积达到了数GB,LOFAR的动辄多少TB,未来平方千米阵的数据采集速率更是当前全球互联网总流量的数倍之巨……面对如此惊人的数据压力,FITS还要声称本格式仅适合顺序读写不宜并行,请问这真的不是在开玩笑吗?也难怪这种古老的格式首先是在各大射电干涉阵失宠的。
- 落后于当代计算机技术的发展:除了读写要求顺序进行因而难以应对海量数据之外,FITS文件的“文件”真的就是单个计算机文件,一旦生成,就需要以整个文件为单位进行操作,从中截取部分数据较为困难,想实现灵活而方便的共享更难。这显然跟流媒体、云存储等新兴的时髦玩意八字不合,给新时代的数据查询和存档带来了诸多不便。
如果单纯看以上这些罪过,这FITS格式差不多该被扔进历史垃圾堆了。不过其他格式能称得上十全十美吗?当然不是。比如前面说到的HDF5,抛开其传说中启用超过三千个(!)CPU核即容易出现不明问题的毛病不论,它本身的数据模型描述也过于灵活,至今也无行业统一标准问世,所以各望远镜自说自话的情况更为明显;更不用提数值模拟领域的情况了,光是VisIt能够支持的HDF5文件输出代码名称列表就能把人看得眼花缭乱。这样看来,如果某种FITS之外的格式想在天文界异军突起,统一标准是首先必须解决的事项,其次就是吸取FITS的教训,明确格式版本、数据模型,也要尽最大可能为今后的发展留出更多、更灵活的空间。
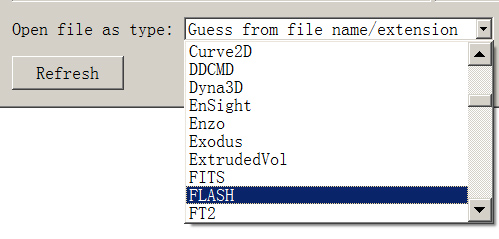
VisIt能够读取的文件格式列表的一部分,除FITS外大抵是数值模拟程序的名称。虽然这些程序输出的都是HDF5文件,但文件的具体组织结构各说各话的现象非常明显。
至于FITS文件的去还是留,谁又能下定论呢?连论文的数十位合作者都不能做到意见统一,遑论整个天文学界。但这文章的目的就是希望吸引更多从业者来关注并思考FITS的种种问题,并积极商讨解决渠道,足矣。